配置hadoop集群一主两从
时间:2017-12-12 点击: 次 来源:网络 作者:佚名 - 小 + 大
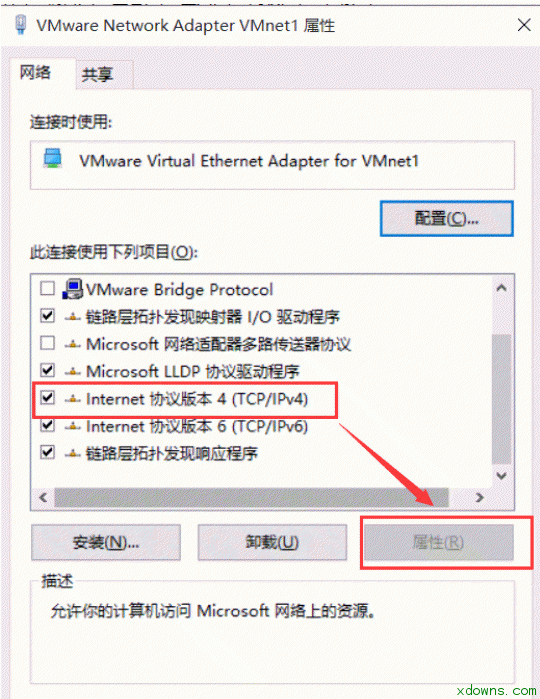
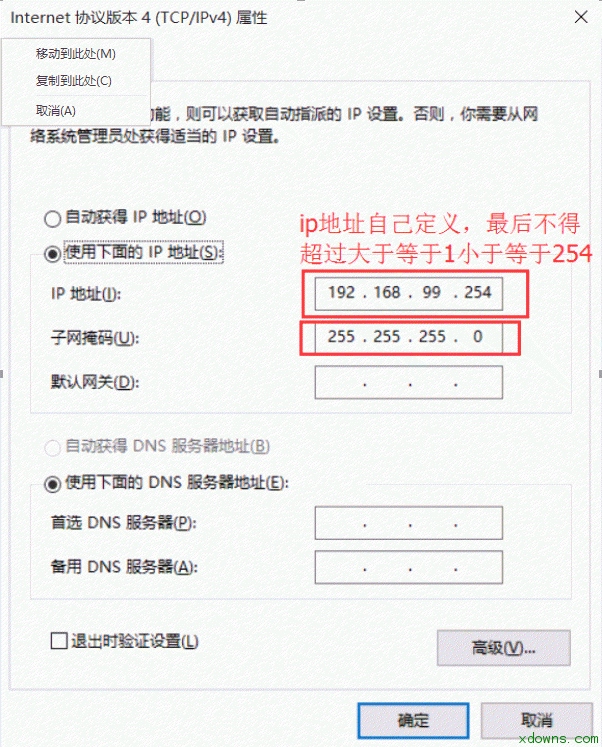
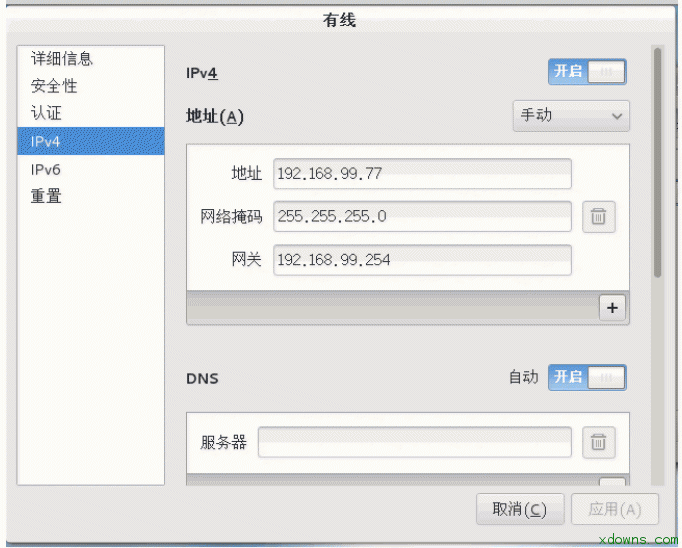
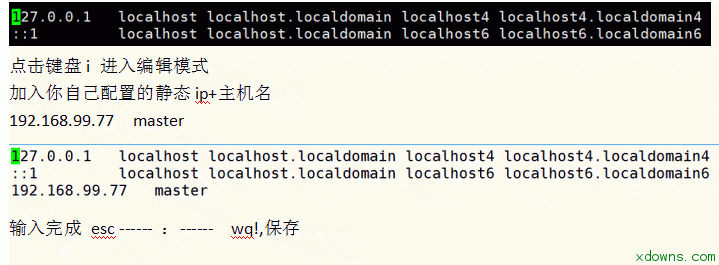
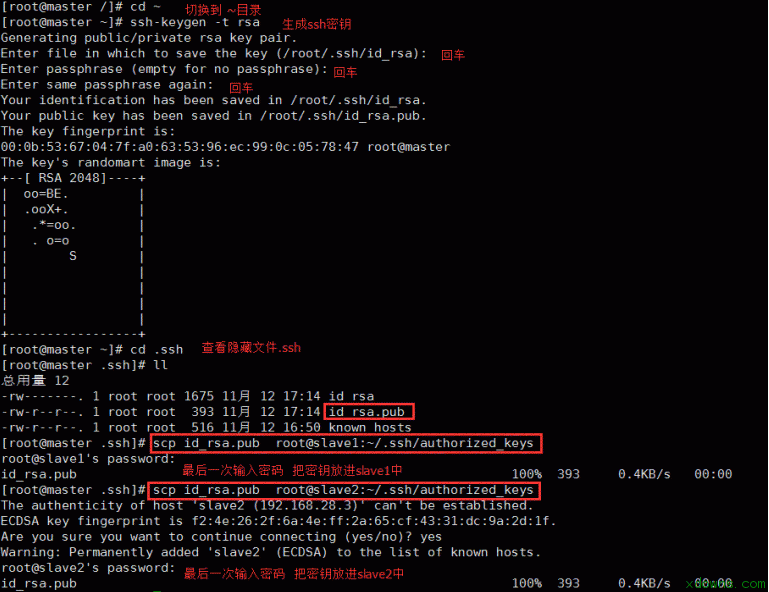
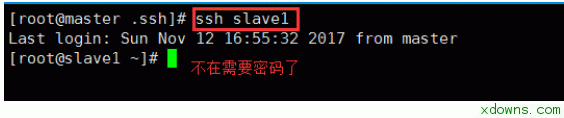
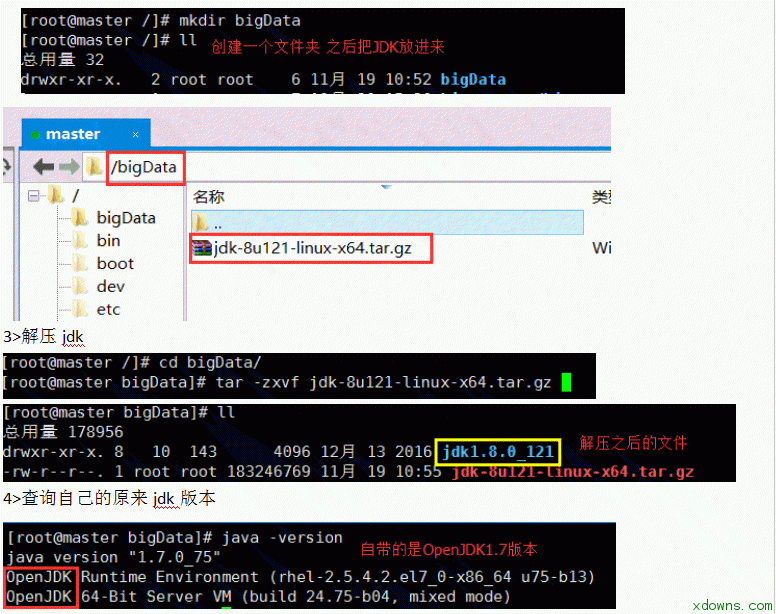
一. 大数据简介 1. 大数据理解误区: 大数据≠Hadoop≠大量的数据≠社交媒体数据≠技术≠一种解决方案 2. 解决方案包含: 数据,人,场景,应用,系统 3. 大数据的四个特点: Variety(多)、Volume(快)、Velocity(杂)、Veracity(垃圾) 4. 数据资产评估维度: 颗粒度、活性、规模、关联度、多维 5. 大数据分布: 商业数据:2% 人为数据:8% 机器数据:90% 6. 过去与现在对比: 过去:随机样本,精确性,因果关系 今天: 全体数据,混沌性,相关关系 7. 现在的时代: 消费者主权时代 消费者自媒体时代 信息大爆炸时代 二.linux基础 1. 修改主机名: 将主机名(永久)修改为master hostnamectl set-hostname master 查看自己主机名是否修改成功 Hostname 2. 设置静态ip 在你自己电脑的更改适配器设置里面 右键属性 虚拟机网络设置为仅主机模式 在网络设置里修改如下图所示 2. 将主机名与静态ip绑定 vi /etc/hosts 2. 关闭防火墙 禁止防火墙开机时启动 systemctl disable firewalld.service 3. ssh免密码登录 设备: Master 192.168.99.77 Slave1 192.168.99.88 Slave2 192.168.99.99 1> 切换到根目录下 cd 2> 使用RSA算法生成秘钥 ssh-keygen -t rsa 测试 2. 安装jdk 1>下载对应jdk 1>使用xftp连接master 1>进入解压之后的jdk目录下 安装Hadoop集群 1. 下载需要的jar包
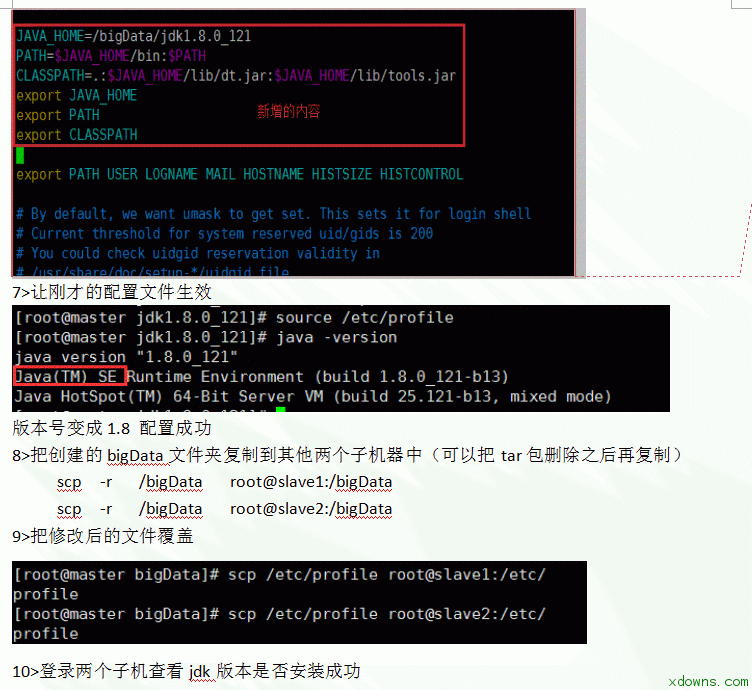
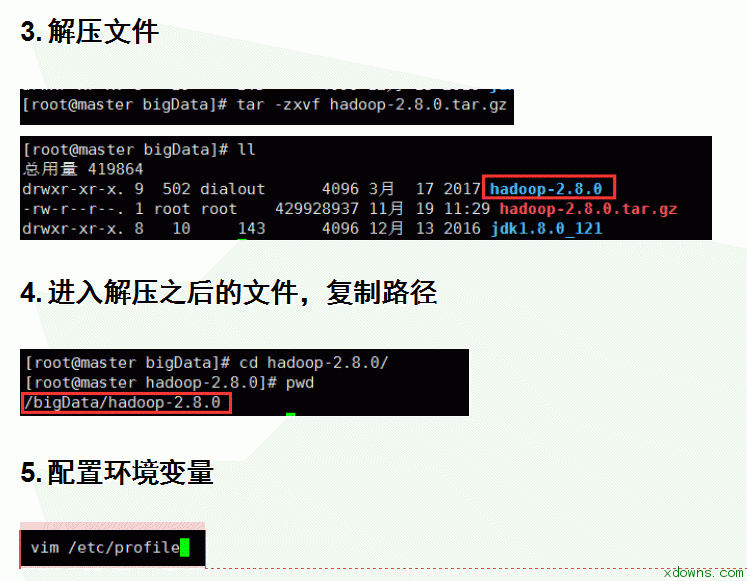
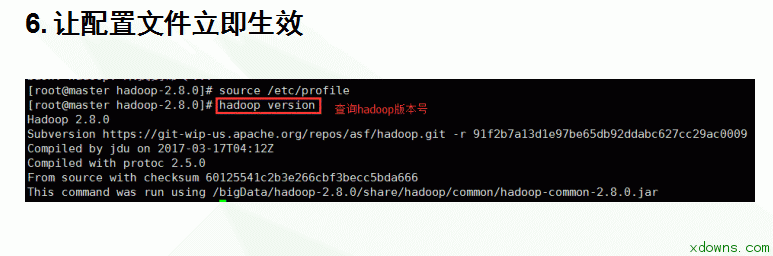
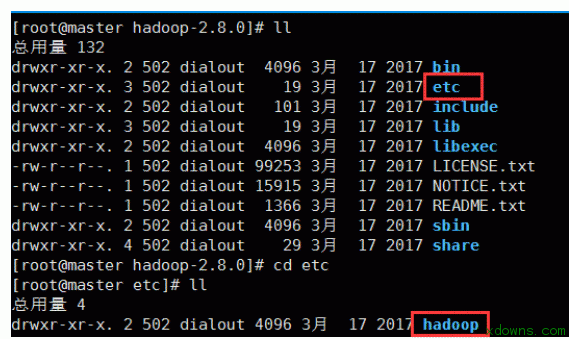
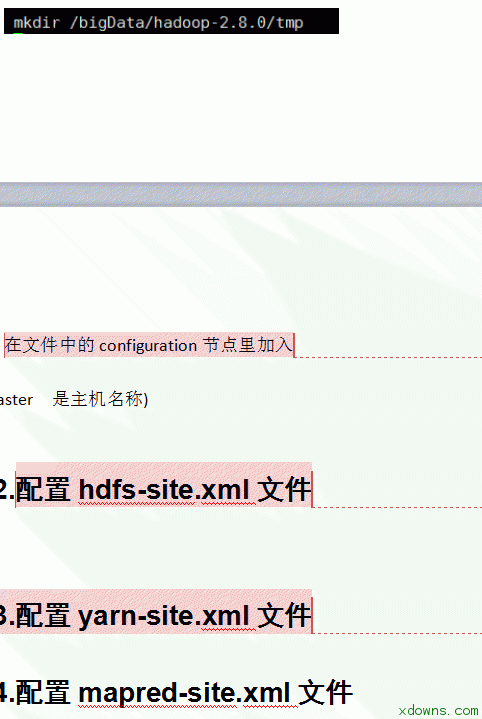
2. 连接xftp 1. 进入hadoop的配置文件夹中开始配置需要的文件 8.配置hadoop-env.sh文件 1> vim hadoop-env.sh 2> 在文件中加入 export JAVA_HOME=/bigData/jdk1.8.0_121 9.配置yarn-env.sh文件 1> vim yarn-env.sh 2> 在文件中加入 export JAVA_HOME=/bigData/jdk1.8.0_121 10. 配置slaves文件 1> vim slaves 2> 删除原有的localhost 3> 在文件中加入 slave1 slave2 11. 配置core-site.xml文件 1> vim core-site.xml 配置mapred-site.xml文件 1> mapred-site.xml.template 是存在的 mapred-site.xml不存在 注意:先要copy一份 cp mapred-site.xml.template mapred-site.xml 然后编辑 vim mapred-site.xml 2> 在文件中新增 15. 把配置好的hadoop文件复制到其他的子机器中 scp -r /bigData/hadoop-2.8.0 root@slave1:/bigData/ scp -r /bigData/hadoop-2.8.0 root@slave2:/bigData/ 16. 把配置好的/etc/profile文件复制到其他的子机器中 进行测试 hadoop version 17. 格式化节点 在master 主机器中运行 hdfs namenode -format 15. 在sbin目录下启动/关闭集群 1> 启动 ./start-all.sh
2> 关闭 ./stop-all.sh sbin文件在hadoop的安装目录的一级列表中
16. 分别在三台电脑使用jps命令验证安装成功
四.WordCout测试 1.准备输出文件
2. 创建input目录 放输出文件 hadoop fs -mkdir /input
3. 准备的输入文件拷贝到 HDFS 上 hadoop fs -put input/f*.txt /input 4. 运行程序 hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount /input /output 输出结果
5. hadoop fs -cat /output/* |

上一篇:tomcat设置问题总结
下一篇:linux双网卡路由配置私网专线